Python の csv モジュールの DictWriter を使ってみます。
DictWriter のドキュメントは こちら です。
DictWriterは辞書型の変数を出力するオブジェクトになります。
DictWriterの基本的な使い方
サンプルコードをお見せします。
コードの詳細は次の章で説明します。
import os
import csv
# 出力する辞書型を作成する。
data = {
'Ken' : { 'Country': 'US', 'Job': 'Artist', 'Age': 56 },
'Alan' : { 'Country': 'Japan', 'Job': 'Carpenter', 'Age': 27 },
'Steven' : { 'Country': 'China', 'Job': 'Artist', 'Age': 40 }
}
filename = 'test_a.csv'
file_path = os.path.join(os.getcwd(), filename)
f = open(file_path, 'w')
fieldnames = data[list(data.keys())[0]].keys() # Dict型データの1列目のKEYを取得する。
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader() # ここでヘッダが書かれる。
for name in data:
writer.writerow(data[name])
f.close()
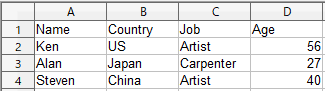
このようなCSVが出力されます。
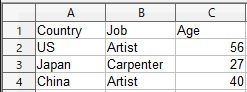
この例では、Country, Job, Ageをヘッダとして、個人の情報をCSVに書き出しています。
名前部分が出力されていないところは後述します。
ヘッダ情報はfieldnamesで渡します。
DictWriterオブジェクト生成時に渡すfieldnamesパラメータは、writerow()するときに存在するKEYを伝えるパラメータです。fieldnamesで渡していないKEYでwriterow()するとエラーになります。
サンプルコードの補足説明
fieldnamesを作り出すコードの説明です。
まずは、辞書型dataパラメータの第1階層のKEYをdata.keys()で取得します。
print(data.keys()) >> dict_keys(['Ken', 'Alan', 'Steven'])
次に、それをList型にします。
print(list(data.keys())) >> ['Ken', 'Alan', 'Steven']
配列の0番目を取得すると、第1階層のKEYの先頭のKEYが取得できます。
print(list(data.keys())[0]) >> Ken
最後に、それを使って第2階層のKEYを取得すれば、fieldnames情報の完成です。
print(data[list(data.keys())[0]].keys()) >> dict_keys(['Country', 'Job', 'Age'])
その後は、csvにヘッダを書き込みます。
writer.writeheader()
そして、辞書型dataパラメータの各要素を書き込んでいきます。
writer.writerow(data[name])
第1階層のKEYも出力させるコードにする
これで CSV ファイルはできたのですが、辞書型dataパラメータのName部分が出力されていません。
Name部分を出力したい場合は、こちらのコードとなります。
import os
import csv
# 出力する辞書型を作成する。
data = {
'Ken' : { 'Country': 'US', 'Job': 'Artist', 'Age': 56 },
'Alan' : { 'Country': 'Japan', 'Job': 'Carpenter', 'Age': 27 },
'Steven' : { 'Country': 'China', 'Job': 'Artist', 'Age': 40 }
}
filename = 'test_b.csv'
file_path = os.path.join(os.getcwd(), filename)
f = open(file_path, 'w')
fieldnames = data[list(data.keys())[0]].keys() # Dict型データの1列目のKEYを取得する。
fieldnames = ['Name'] + list(fieldnames) # "Name"キーを先頭に追加する。
writer = csv.DictWriter(f, fieldnames=fieldnames)
writer.writeheader() # ここでヘッダが書かれる。
for name in data:
data_new = {'Name': name} # "Name"キーを含むDict型を新たに作成する。
data_new.update(data[name]) # "Name"キー以外の要素を追加する。
writer.writerow(data_new)
f.close()