matplotlibでグラフを作ったら凡例を入れてわかりやすくしたいんですが、凡例とグラフが被ってしまうことってありますよね?そこで、凡例を横並びにしてグラフのスペースを上手く使えるようにしてみます。
凡例を横並びにするための引数はncols
先に言ってしまうと、グラフの凡例を横並びにするのは、ax.legend関数のncolsという引数です。名前の通り、凡例の列数を指定するパラメータになります。
https://matplotlib.org/stable/api/_as_gen/matplotlib.axes.Axes.legend.html
出典: matplotlib.org

上記に記載されているとおり、ncolというパラメータも下位互換のために残されていますが非推奨となります。ncolsを使います。
グラフ化するデータの作成
グラフ化するサンプルデータは何でもいいのですが、近似曲線のグラフにします。
乱数のデータ
まずは、近似曲線を描くためのデータを用意します。乱数にします。
# X軸の値
x = [i for i in range(20)]
# Y軸の値: 整数(0から20の間)の乱数の配列
y = [random.randint(0, 20) for i in range(len(x))]
# list型をnumpy.ndarray型に変換する。
x = np.array(x)
y = np.array(y)
print(f'x: {x}')
print(f'y: {y}')
print(f'type(x): {type(x)}')
print(f'type(y): {type(y)}')
x: [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19]
y: [18 1 2 10 0 2 15 4 3 0 8 19 2 5 6 3 19 5 15 14]
type(x): <class 'numpy.ndarray'>
type(y): <class 'numpy.ndarray'>
乱数の作成方法は、過去記事より。
 Pythonで整数と小数の乱数を生成するrandomモジュール
Pythonで整数と小数の乱数を生成するrandomモジュール
近似曲線のデータ
近似曲線はnumpy.polyfit関数を使って、1次から3次までのものを算出します。
# 1次近似直線の算出。 p1 = np.polyfit(x, y, 1) y1 = p1[0] * x + p1[1] # 2次近似曲線の算出。 p2 = np.polyfit(x, y, 2) y2 = p2[0] * x**2 + p2[1] * x + p2[2] # 3次近似曲線の算出。 p3 = np.polyfit(x, y, 3) y3 = p3[0] * x**3 + p3[1] * x**2 + p3[2] * x + p3[3]
近似曲線の算出方法は、過去記事より。
Pythonでグラフの近似直線と近似曲線を描く
グラフの作成
デフォルトの凡例(デフォルトはncols=1)
まずは、ncols引数を設定せずにそのままグラフを描きます。
# グラフを描く。 fig = plt.figure() ax = fig.add_subplot() ax.plot(x, y, label='original', marker='.', alpha=0.5, linewidth=0) ax.plot(x, y1, label='1-demension', marker='.', alpha=0.5) ax.plot(x, y2, label='2-demension', marker='.', alpha=0.5) ax.plot(x, y3, label='3-demension', marker='.', alpha=0.5) ax.legend() plt.show()
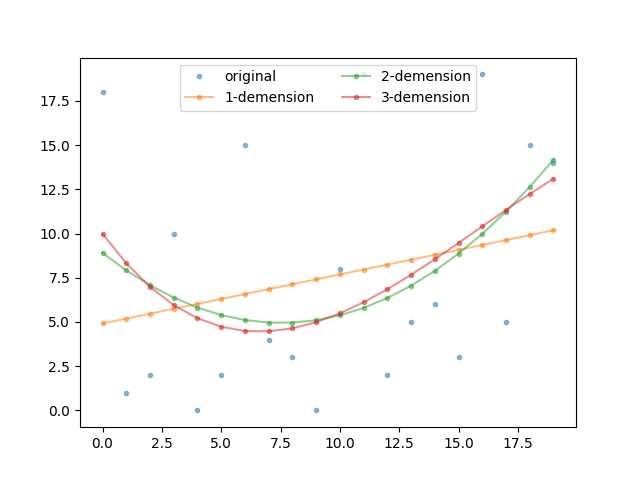
デフォルトの凡例は、下図のように縦に並べられます。
凡例数を自動取得してncolsに設定する
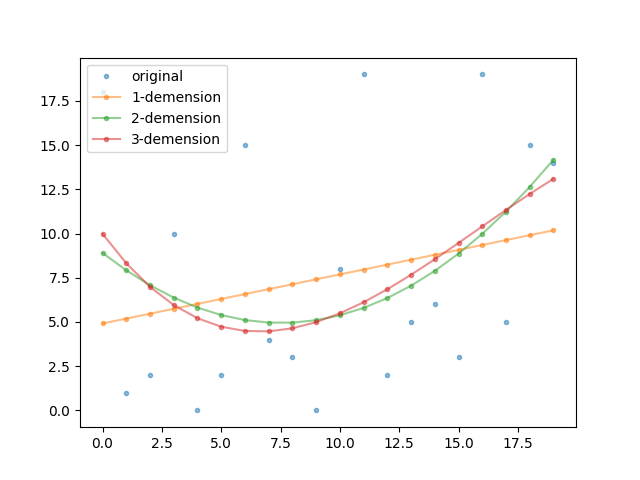
次に、凡例を横並びにしてグラフを描きます。凡例の個数がいくつでも対応できるように、凡例数を自動取得しています。
# グラフを描く。 fig = plt.figure() ax = fig.add_subplot() ax.plot(x, y, label='original', marker='.', alpha=0.5, linewidth=0) ax.plot(x, y1, label='1-demension', marker='.', alpha=0.5) ax.plot(x, y2, label='2-demension', marker='.', alpha=0.5) ax.plot(x, y3, label='3-demension', marker='.', alpha=0.5) # 凡例の個数を算出する。 num = len(ax.legend().get_texts()) # 凡例の列数をncolsで設定する。 ax.legend(ncols=num) plt.show()
ncols引数で横並びにすると、以下のようになります。しかし、今回の例はグラフの枠からはみ出してしまっているので、横並びにしたことが良い結果になっていないようです。

ncolsに固定値を設定する
上のグラフでは、凡例がグラフの枠からはみ出してしまったので、はみ出さないように凡例の列数に固定値を設定して見ました。
# グラフを描く。 fig = plt.figure() ax = fig.add_subplot() ax.plot(x, y, label='original', marker='.', alpha=0.5, linewidth=0) ax.plot(x, y1, label='1-demension', marker='.', alpha=0.5) ax.plot(x, y2, label='2-demension', marker='.', alpha=0.5) ax.plot(x, y3, label='3-demension', marker='.', alpha=0.5) # 凡例の列数を固定値2で設定する。 ax.legend(ncols=2) plt.show()
凡例を横並びすると問題がある場合は、ncolsに適切な値を入れてしまうこともできます。今回は、凡例は2列にする場合が見栄え的には一番いいかもしれません。